连云港信息化数据采集价格
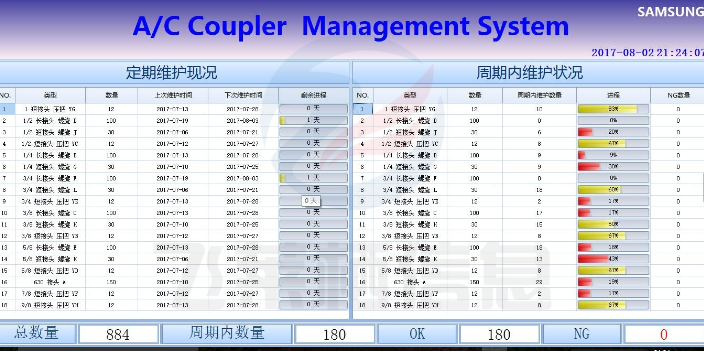
围绕规划、系统与实施三个**阶段工作,面向运维数据的全生命周期与业务导向结果,从数据的整体规划、运维数据源、数据采集、数据的计算与处理、指标管理体系的规划与实施、专业运维数据库的建立、数据的典型应用场景等多角度进行思考。但需要正视的是我们对运维数据的认识及应用还处于皮毛阶段,虽有理念但缺乏必要的、可执行的方法。随着运维数据平台的建设,将极有可能出现当前大数据领域出现的数据孤岛、数据不可用、数据质量不高、融合应用难、有数据不会用等诸多问题。上述问题,在当前运维领域资源投入不足时显得尤其重要。借鉴大数据领域数据治理的经验,反思运维数据平台建设应该关注的问题,减少不必要的坑,做好运维数据治理,让运维数据更好用、用得更好,完善运维数字化工作空间。在运维领域,运维数据分布在大量的机器、软件和“监管控析”工具上,除了上面大数据领域提到的数据孤岛、质量不高、数据不可知、数据服务不够的痛点外,运维数据还有以下突出痛点:一、资源投入不够。从组织的定位看,运维属于企业后台中的后台部门。数据采集可以通过城市智能管理系统实现对城市运行状况的实时监测。连云港信息化数据采集价格
随着智能终端设备的飞速发展,网络技术的持续升级,产生的数据越来越多,将有更多的企业需要大数据技术,大数据技术逐渐地演变成一种应用***的平民架构。在上述背景下,一些企业获取的数据逐步增长,达到了一个新的量级。基于之前的积累,企业在数据清洗、分类等环节已经具备了相应的能力,但仍不能让数据实现比较大化的价值。为了让处理人员能更专注于数据的理解以及后续分析处理,将长期业务进行固化处理,把它开发成一个产品,以解放出一部分人力去完成更多的任务,挖掘出更多数据间的隐性关联。但是在设计这个产品的时候,由于受限原始网络结构、通信策略、防火墙布局等种种限制,很多需要相互协作的平台所对应的部署机器是无法相互间通信的。 宁波哪里有数据采集大概多少钱数据采集在医疗健康监测中起着至关重要的作用,例如心率监测和睡眠追踪。
也正是坚守于此,过去五年,不论是在数据采集技术,还是数据治理方案等方面,我们都做了很多的工作,也帮助了很多的客户。比如我们建立强大的数据采集SDK研发团队,并将SDK全部开源,也维护着近1500人的开源讨论社群,同时不断向业界输出我们的积累、经验和沉淀,让数据采集技术不再神秘,更让数据采集技术的生态更好、更健康的向前发展。二、业内常见的数据采集方案目前,市面上常见的埋点方式主要有三种:代码埋点、全埋点和可视化埋点。1.代码埋点代码埋点,即客户端集成SDK,在客户端启动的时候初始化SDK,然后在某个事件(行为)发生时,客户端显示调用SDK的接口触发相应的事件。代码埋点,是**常见的埋点方式,同时也是“*****”的埋点方式。其优点如下:(1)可以精细控制埋点;(2)可以灵活添加自定义事件和属性;(3)可以满足更精细化的分析需求。同时,代码埋点也有一些缺点:(1)前期埋点代价比较大;(2)埋点的变更,需要伴随客户端的发版。2.全埋点全埋点,也叫无埋点、**埋点、无痕埋点、自动埋点等,是指无需开发工程师写代码或者只写少量的代码,就能预先自动采集用户的所有行为数据,然后在数据分析产品上通过点选和配置,来筛选要分析和统计的对象。
②计算变量:计算变量的目的是调用决策引擎;③调用决策引擎:部署有催收策略;④确定催收策略:将变量传给决策引擎后,决策引擎会返回确定的催收策略。产生“是否催收、自己催or外包、如何催、分配给哪位催收员、什么时候打电话、用哪个沟通模板”等类型风险决策;⑤分配催收任务:根据案件催收难度分配给不同催收员;⑥记录催收结果:将催收结果进行归类,如:失联、无人接听、占线、承诺还款等。四、征信平台系统策略和模型的基础是数据,数据分为内部数据和外部数据,调用外部数据就是由征信平台系统进行。**功能模块:调用、解析、征信数据库①调用:将客户参数调用传给外部数据源相关机构,如:人行征信报告、百行征信报告、NCIIC等,相关**以封装加密形式返回,返回的数据一般包括客户的个人工作单位、婚姻、学历、***开卡、还款情况等;②解析:解析有两层功能含义,一是***返回的数据,二是将文本串信息进行标准化,使数据变成能够在标准数据库中存储的形式;③征信数据库:储存解析好的征信数据。五、决策引擎系统它是一种基于特地业务场景开发的定制引擎,中间充当一个变量计算和决策判断的功能,以“处理变量然后输出变量”的方式将风控决策落地。数据采集可以通过在线教育平台获取学生学习行为和成绩。
我们对部分**平台进行参考性的自主研发,重构实时采集系统,同时对底层实时计算引擎Storm使用Java进行重写等;第三代是纯自主研发的阶段,第三代的**平台—高性能分布式机器学习平台Angel,是腾讯和北大等高校联合研发,具有完全知识产权。我们一直是开源的受益者,从Hadoop到Spark到Storm……我们的发展离不开社区,我们弱小的时候依赖开源社区,我们成长后又积极回馈社区。其实早在2014年,我们就把腾讯自己的Hive版本进行开源,它对Oracle语法兼容等特性广受欢迎。我们第三代****的高性能分布式机器学习平台Angel在2017年就开源了,2018年还进一步捐献给Linux基金会。2019年,我们一口气开源了四大平台:实时数据采集平台TubeMQ(捐献给Apache社区)、资源管理平台TKEStack、分布式数据库TBase以及腾讯版本的OpenJDK—KonaJDK。我们有几十个项目的PMC和提交者及更大量的贡献者,每天都为社区贡献代码。通过开源进行技术上的协同,可聚拢人才,一个好的项目能吸引很多***的开发者,有利于形成一个优良的技术生态,有利于推动技术进步。这也是我们选择开源的原因。来自开源、回馈开源、坚持开源,这可以说是腾讯大数据平台十年发展的技术理念。数据采集可以通过各种手段进行,包括传感器、调查问卷、网络爬虫等。宁波哪里有数据采集大概多少钱
数据采集的结果可以用于制定营销策略、产品研发和业务决策。连云港信息化数据采集价格
然后将采集得到的数据,通过实时或者批量的方式,向后进行传输;对于这些传输过来的数据,选择合适的数据模型进行ETL和建模,并且根据后续的应用选择合适的存储方案;在数据完成建模并且存储下来之后,就可以对数据进行统计、分析和挖掘等数据应用;而这些数据应用的结果,一方面,可以通过数据可视化的方式,直接展现,并帮助我们做出各种产品、运营和商业等方面的决策;另一方面,这些数据应用的结果,也可以直接反馈给产品,以类似于「猜你喜欢」的产品形态,直接作用在产品上。很显然,在一个典型的数据应用上,数据采集是***个环节,是源头,是一切数据应用的起点。如果数据采集没有做好,影响了整体的数据质量,那么,在后面环节再想进行弥补,其代价会很大,效果也会大打折扣。**终的数据应用,以及基于应用得到的决策与反馈的质量也必然会受到影响。从这个意义上来讲,无论我们如何强调数据采集的重要性,也都不为过。正是因为我们意识到了数据采集的重要性,神策数据的愿景随之诞生,即“帮助中国三千万企业重构数据根基,实现数字化经营”,希望通过我们的努力,能够帮助我们的客户和合作伙伴更好、更***地采集数据,从而**大化地发挥数据的价值。连云港信息化数据采集价格
上一篇: 宁波定制MES价格
下一篇: 上位机ERP对接系统公司